How an Evoked Response BCI works¶
Evoked Response Brain Computer Interfaces, which are also called or Event Related Potential (ERP) BCIs, are a general class of Brain Computer Interface which rely on detecting the brain response to known external stimuluation. This type of BCI is one of the most successful BCI types for communication purposes, as many options can be presented in parallel and selected between – allowing one to for example implement a full keyboard for text generation. Further, whilst the most successfull ERP-BCIs have used discrete visual stimuli, the same basic approach can be used for other discrete stimlus types (such as auditory or tactile) or even continuous stimulus, such as natural speech https://doi.org/10.3389/fnins.2016.00349.
The schematic below illustrates the general principles of (visual) ERP BCIs:
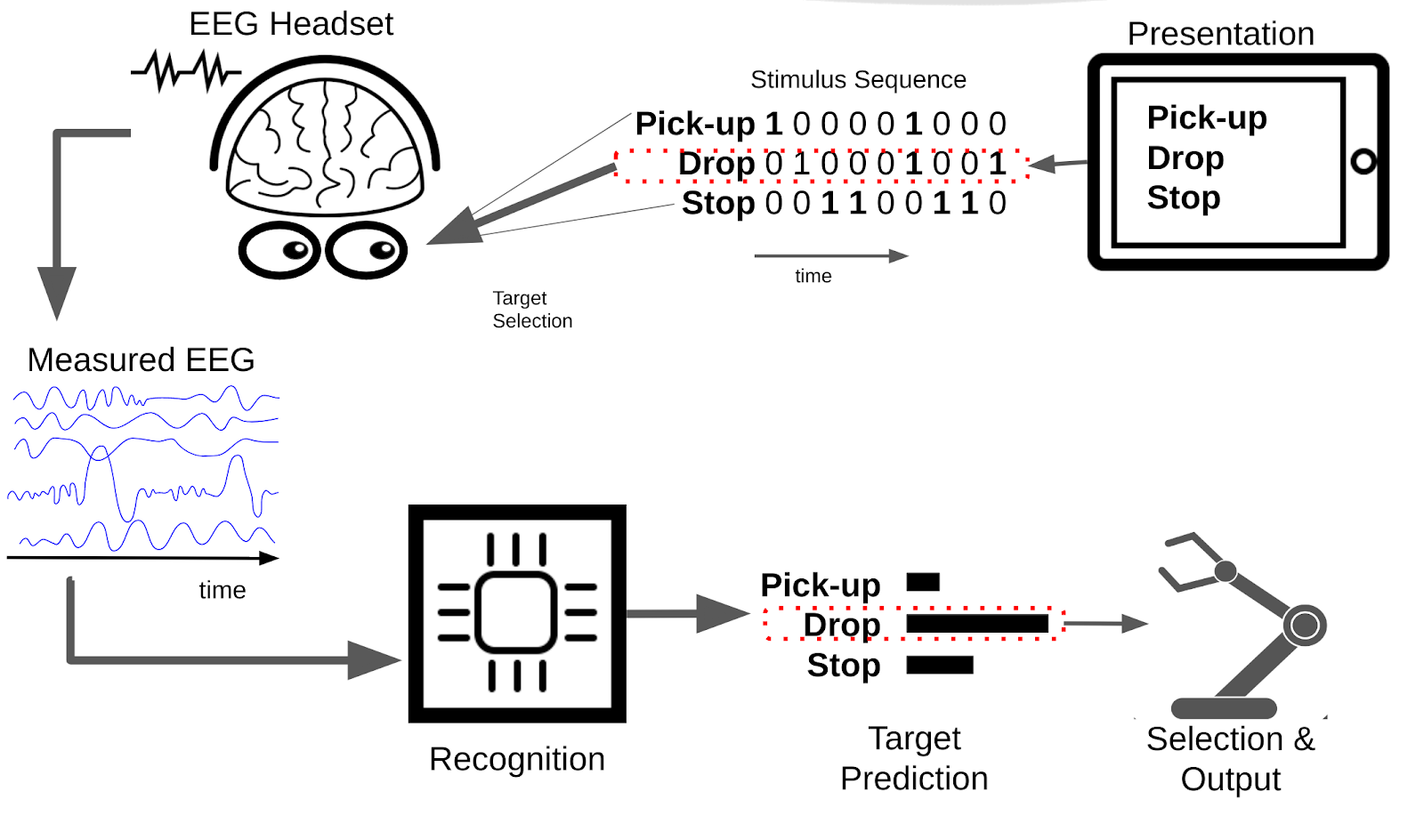
To briefly describe this schematic, the aim of a BCI in general is to control an output device (in this case a robot arm) with your thoughts. In this specific case we control the robot arm by selecting actions perform as flickering virtual buttons on a tablet screen. (See Mindaffect LABS for a video of the system in action) :
- Presentation: displays a set of options to the user, such as which square to pick in a tic-tac-toe game, or whether to pick something up with a robot arm.
- Each of the options displayed to the user then flickers with a given unique flicker sequence (or stimulus-sequence) with different objects getting bright and dark at given times.
- The user looks at the option they want to select to select that option. (Or in a non-visual BCI ‘attends to’ or ‘concentrates on’ the option they want to select.)
- The users brain response to the presented stimulus is measured by EEG - due to the users focus on their target object, this EEG signal contains information on the flicker-sequence of the target object.
- The recognition system uses the measured EEG and the known stimulus sequence to generate predictions for the probability of the different options being the users target option.
- Selection takes the predictions from the recogniser and any prior knowledge of the application domain (such as a language model when spelling words) to decide when an option is sufficiently confidently predicted to be selected and output generated.
- Finally, Output generates the desired output for the selected option, for example moving the robot arm to perform the selected option.